More about forecasting in cienciadedatos.net
- ARIMA and SARIMAX models with python
- Time series forecasting with machine learning
- Forecasting time series with gradient boosting: XGBoost, LightGBM and CatBoost
- Forecasting time series with XGBoost
- Global Forecasting Models: Multi-series forecasting
- Global Forecasting Models: Comparative Analysis of Single and Multi-Series Forecasting Modeling
- Probabilistic forecasting
- Forecasting with deep learning
- Forecasting energy demand with machine learning
- Forecasting web traffic with machine learning
- Intermittent demand forecasting
- Modelling time series trend with tree-based models
- Bitcoin price prediction with Python
- Stacking ensemble of machine learning models to improve forecasting
- Interpretable forecasting models
- Mitigating the Impact of Covid on forecasting Models
- Forecasting time series with missing values

Data drift¶
In the context of forecasting and machine learning, data drift refers to a change in the statistical properties of the input data over time compared to the data on which the model was originally trained. When this happens, the model may start to produce less accurate or unreliable predictions, since it no longer generalizes well to the new data distribution.
Data drift can take several forms:
Covariate Drift (Feature Drift): The distribution of the input features changes, but the relationship between features and target remains the same. Example: A model was trained when a feature had values in a certain range. Over time, if that feature shifts to a different range, covariate drift occurs.
Prior Probability Drift (Label Drift): The distribution of the target variable changes. Example: A model trained to predict energy consumption during a season may fail if seasonal patterns change due to external factors.
Concept Drift: The relationship between input features and the target variable changes. Example: A model predicting energy consumption from weather data might fail if new technologies or behaviors alter how weather affects energy usage.
Detecting and addressing data drift is crucial for maintaining model reliability in production environments. Common strategies include:
Monitoring input data during prediction to detect changes early.
Tracking model performance metrics (e.g., accuracy, precision, recall) over time.
Retraining models periodically with recent data to adapt to evolving conditions.
Skforecast includes two dedicated classes for data drift detection:
PopulationDriftDetector: detects changes at the population level, helping identify when a forecasting model should be retrained.RangeDriftDetector: detects changes at the single-observation level, suitable for validating input data during the prediction phase.
Drift detection during model training¶
The ultimate goal of drift detection is to answer a simple but important question: Is the distribution of new data different from the distribution of the training data?
When there is no time component and the data points are independently and identically distributed (i.i.d.), this question is usually addressed with statistical tests. These tests measure some form of distance between the distributions of the two datasets and then calculate a probability value (p-value) to determine whether the difference is large enough to suggest a significant change.
However, this approach cannot be directly applied to time series data, where the distribution naturally changes over time due to patterns such as seasonality or trends. Detecting drift in this context requires methods that account for these expected temporal dynamics.
To better illustrate this concept, the following example compares two months of a time series with the full dataset. In this case, the tested months are as expected, meaning no drift should be detected.
# Libraries
# ==============================================================================
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from skforecast.datasets import fetch_dataset
from skforecast.plot import set_dark_theme
from skforecast.drift_detection import PopulationDriftDetector
from scipy.stats import ks_2samp
# Data
# ==============================================================================
data = fetch_dataset('bike_sharing', verbose=False)
data = data[['temp', 'hum']]
display(data.head())
data_train = data.iloc[: 9000].copy()
data_new = data.iloc[9000:].copy()
| temp | hum | |
|---|---|---|
| date_time | ||
| 2011-01-01 00:00:00 | 9.84 | 81.0 |
| 2011-01-01 01:00:00 | 9.02 | 80.0 |
| 2011-01-01 02:00:00 | 9.02 | 80.0 |
| 2011-01-01 03:00:00 | 9.84 | 75.0 |
| 2011-01-01 04:00:00 | 9.84 | 75.0 |
set_dark_theme()
fig, ax = plt.subplots(figsize=(8, 3))
test_data_starts = '2011-12-01 22:00:00'
test_data_ends = '2012-01-31 23:00:00'
reference_data = data_train.loc[:, 'temp'].copy()
test_data = data_train.loc[test_data_starts:test_data_ends, 'temp'].copy()
reference_data.plot(ax=ax, label='Reference data')
test_data.plot(ax=ax, label='New data')
ax.legend();

A Kolmogorov-Smirnov test is used to compare the distributions of the training data and the new data. The null hypothesis states that both samples come from the same distribution. If the p-value is below a certain threshold (commonly 0.05), we reject the null hypothesis, indicating that the distributions are significantly different, suggesting drift.
# Kolmogorov-Smirnov test to compare both data sets
# ==============================================================================
ks_2samp(reference_data, test_data)
KstestResult(statistic=np.float64(0.4571829521829522), pvalue=np.float64(8.54562775188432e-166), statistic_location=np.float64(18.86), statistic_sign=np.int8(-1))
# Plots to compare both data sets
# ==============================================================================
fig, axs = plt.subplots(ncols=2, figsize=(9, 3))
sns.kdeplot(reference_data, label='reference data', color='#30a2da', ax=axs[0])
sns.kdeplot(test_data, label='test data', color='red', ax=axs[0])
axs[0].set_title('Distribution Comparison')
axs[0].set_ylabel('Density')
axs[0].legend()
sns.ecdfplot(reference_data, label='reference data', color='#30a2da', ax=axs[1])
sns.ecdfplot(test_data, label='test data', color='red', ax=axs[1])
axs[1].set_title('Cumulative Distribution Comparison')
axs[1].set_ylabel('Cumulative Probability')
axs[1].legend();

The statistical tests and the visualizations presented above show a clear difference between the distributions although we know that no drift is present. This highlights the importance of using methods specifically designed for time series data when detecting drift, as traditional statistical tests may not be suitable due to the inherent temporal dependencies and patterns in such data.
Distance-Based framework for temporal drift detection¶
This framework implements a distance-based, data-driven approach to detect temporal drift — changes in the underlying data distribution over time — within time series data. It constructs an empirical baseline of normal behavior from historical (reference) data and uses it to assess whether newly observed data deviates significantly from the established norm.
The approach is both model-agnostic and distance-agnostic: any statistical distance or divergence measure that quantifies dissimilarity between data samples can be employed (e.g., Kolmogorov–Smirnov, Chi-squared, Jensen–Shannon divergence, or other appropriate metrics).
1. Reference Phase — Estimating the Empirical Distribution¶
The first step is to characterize the natural variability of the time series under stable conditions.
Select a reference window
Choose a historical segment of the time series that represents stable and drift-free behavior. This segment serves as the reference dataset.Segment the reference data
Divide the reference time series into non-overlapping chunks of equal length: $$ \{ C_1, C_2, \ldots, C_n \} $$
Each chunk $C_i$ corresponds to a fixed temporal window (e.g., one week, one month, or a fixed number of samples).Compute pairwise distances
For each chunk $C_i$, compute its distance from the remainder of the reference dataset (or a representative aggregation thereof).
This produces a collection of distances: $$ \mathbb{D}_{ref} = \{ d_1, d_2, \ldots, d_n \} $$Build the empirical distribution
The set $\mathbb{D}_{ref}$ represents the distribution of distances under normal (non-drifting) conditions. It quantifies the typical level of dissimilarity between stable data segments.Define a drift threshold
Select a quantile (e.g., the 95th percentile) from the empirical distribution $\mathbb{D}_{ref}$ as the drift threshold: $$ \tau = Q_{0.95}(\mathbb{D}_{ref}) $$
Any distance greater than $\tau$ indicates a deviation beyond what is expected under normal variability.
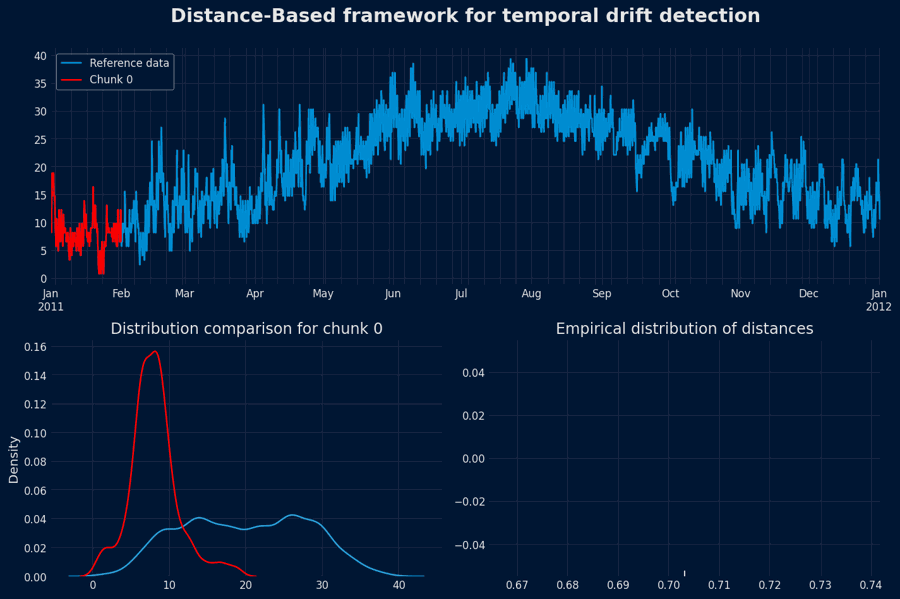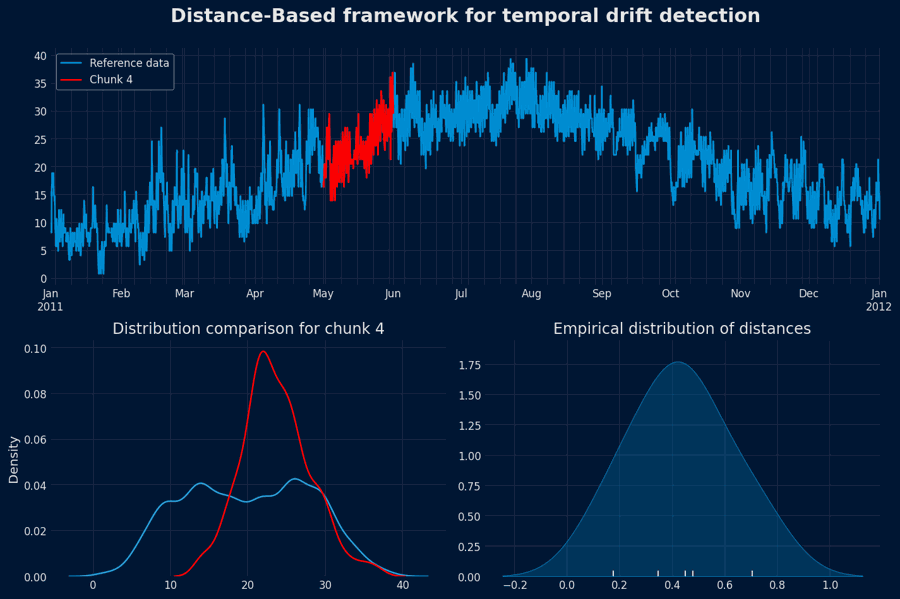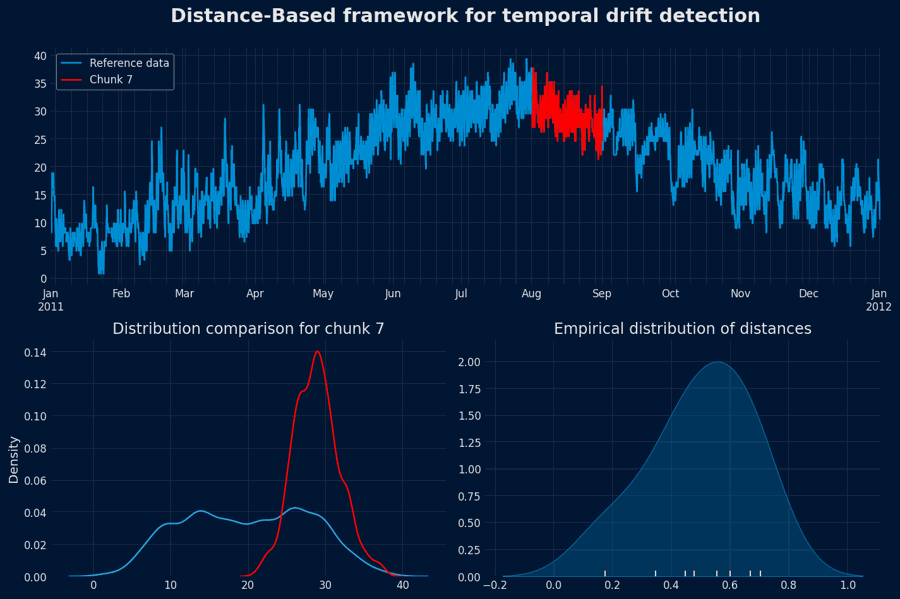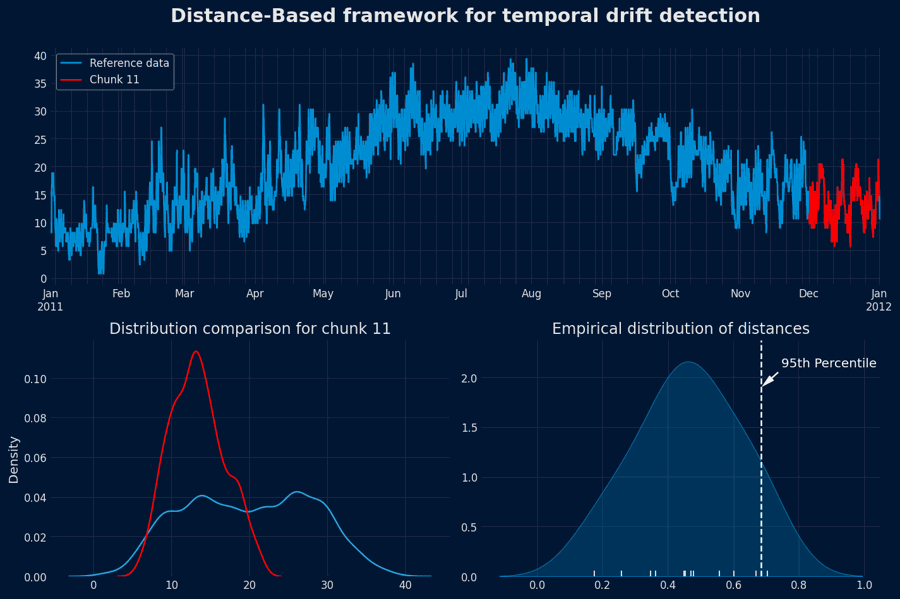
Population Drift Detection - Animation
2. Monitoring Phase — Detecting Drift in New Data¶
Once the baseline distribution is established, new data can be continuously evaluated for drift.
Chunk new data
As new observations become available, segment them into chunks of the same length used in the reference phase: $$ \{ C'_1, C'_2, \ldots, C'_m \} $$Compute distances to the reference
For each new chunk $C'_j$, compute its distance to the reference baseline (either to all reference chunks or to an aggregated representation of the reference distribution).Compare against the threshold
- If $d(C'_j, \text{reference}) \leq \tau$, the data is consistent with the reference distribution.
- If $d(C'_j, \text{reference}) > \tau$, flag the chunk as exhibiting potential drift.
Interpretation
A flagged chunk suggests that the new data segment differs significantly from historical norms, implying a possible population drift or concept shift. Such cases may warrant further investigation, model retraining, or data pipeline adjustments.
PopulationDriftDetector¶
The PopulationDriftDetector is designed to detect feature drift and label drift in time series data. It evaluates whether the distribution of the input variables (both target and exogenous) remains consistent with the data used to train the forecasting model.
By comparing recent observations with the training data, the detector identifies significant distributional changes that may indicate the model needs retraining.
The statistical metrics used depend on the data type:
Numerical features: Kolmogorov–Smirnov statistic and Jensen–Shannon distance.
Categorical features: Chi-squared statistic and Jensen–Shannon distance.
The API follows the same design principles as Skforecast forecasters:
The same data used to train a forecaster can also be used to fit a
PopulationDriftDetector.When new historical data becomes available (i.e., multiple new observations), the
predictmethod can be used to check for drift.If drift is detected, users should analyze its cause and consider retraining or recalibrating the forecasting model.
✏️ Note
This implementation is inspired by NannyML's DriftDetector, but provides a lightweight adaptation tailored to Skforecast’s time series context.
- Memory-efficient: The detector does not store the full reference data. Instead, it keeps only the precomputed statistics required to evaluate drift efficiently during prediction.
- Empirical thresholds: In addition to standard deviation-based thresholds, thresholds can be derived from the specified quantile of the empirical distributions computed from the reference data chunks using leave-one-chunk-out to avoid self-comparison bias.
- Out-of-range detection: It also checks for out-of-range values in numerical features and for unseen categories in categorical features.
- Multiple time series support: It can handle multiple time series, each one with its own exogenous variables.
To illustrate how drift detection works, the dataset is divided into a training set and a new data partition, simulating a real-world scenario where additional data becomes available after the model has been trained.
To emulate data drift, the variable temp in the new data partition is intentionally modified:
June: Temperatures are increased by +10 ºC.
July: Temperatures are increased by +20 ºC.
October: Temperatures are replaced by a constant value equal to the mean of the original data. Although this value lies within the original range, its lack of variability makes it statistically atypical.
December: Temperatures are decreased by -10 ºC.
The variable hum remains unchanged throughout the new data partition, serving as a control variable to demonstrate that the drift detector correctly identifies no drift when none exists.
# Data
# ==============================================================================
data = fetch_dataset('bike_sharing', verbose=False)
data = data[['temp', 'hum']]
data_train = data.iloc[: 9000].copy()
data_new = data.iloc[9000:].copy()
# Inject changes in the distribution
# ==============================================================================
data_new_drift = data_new.copy()
# Add +10 to observations in June 2012
data_new_drift.loc['2012-06-01 00:00:00':'2012-06-30 23:00:00', 'temp'] = (
data_new_drift.loc['2012-06-01 00:00:00':'2012-06-30 23:00:00', 'temp'] + 10
)
# Add +20 to observations in July 2012
data_new_drift.loc['2012-07-01 00:00:00':'2012-07-31 23:00:00', 'temp'] = (
data_new_drift.loc['2012-07-01 00:00:00':'2012-07-31 23:00:00', 'temp'] + 20
)
# Constant mean value in October 2012
data_new_drift.loc['2012-10-01 00:00:00':'2012-10-31 23:00:00', 'temp'] = (
data_new_drift.loc['2012-10-01 00:00:00':'2012-10-31 23:00:00', 'temp'].mean()
)
# Subtract -10 from December 2012
data_new_drift.loc['2012-12-01 00:00:00':'2012-12-31 23:00:00', 'temp'] = (
data_new_drift.loc['2012-12-01 00:00:00':'2012-12-31 23:00:00', 'temp'] - 10
)
# Plot
# ==============================================================================
set_dark_theme()
fig, ax = plt.subplots(figsize=(8, 4))
data_train.loc[:, 'temp'].plot(ax=ax, label='Train')
data_new_drift.loc[:, 'temp'].plot(ax=ax, label='New data with drift', color='red')
data_new.loc[:, 'temp'].plot(ax=ax, label='New data', color='green')
ax.axhline(data_train['temp'].max(), color='white', linestyle=':', label='Max Train')
ax.axhline(data_train['temp'].min(), color='white', linestyle=':', label='Min Train')
ax.legend();

When creating a PopulationDriftDetector instance, three key arguments must be specified:
chunk_size: Defines the number of observations in each data chunk used to compare distributions. A smaller chunk size enables more frequent drift checks but can increase false positives due to higher variability. Conversely, a larger chunk size smooths out variability but may delay drift detection. The optimal value depends on the trade-off between sensitivity and stability for the specific application and dataset.threshold: Specifies the threshold used to determine whether drift has occurred. The higher the threshold, the more conservative the detector will be in flagging drift.threshold_method: Determines how the threshold is calculated from the empirical distribution. Options are:'std'for standard deviation-based thresholds. Thresholds are calculated as mean + threshold * std. This method is computationally faster since it does not require leave-one-chunk-out.'quantile'for quantile-based thresholds. Thresholds are derived from the specified quantile of the empirical distribution using leave-one-chunk-out to avoid self-comparison bias.
max_out_of_range_proportion: Maximum allowed proportion of observations outside the reference value range for numeric features. If the proportion of out-of-range values in a new data chunk exceeds this threshold, drift is flagged for the corresponding feature. This parameter provides an additional safeguard against distribution shifts that manifest as values falling outside the observed reference range.
# Fit detector using the training data
# ==============================================================================
detector = PopulationDriftDetector(
chunk_size = 'MS', # Monthly chunks
threshold = 3,
threshold_method = 'std',
max_out_of_range_proportion = 0.1
)
detector.fit(data_train)
detector
PopulationDriftDetector
General Information
- Chunk size: MS
- Threshold: 3
- Threshold method: std
- Max out of range proportion: 0.1
- Is fitted: True
- Skforecast version: 0.23.0
Fitted features
-
['temp', 'hum']
Once the detector has been fitted, it can be used to evaluate new data using the predict method. This method returns two DataFrames:
Detailed results: Contains information about the computed statistics, thresholds, and drift status for each data chunk.
Summary results: Provides an overview showing the number and percentage of chunks where drift was detected.
# Detect drift in new data
# ==============================================================================
drift_results, drift_summary = detector.predict(data_new_drift)
# Drift detailed results
# ==============================================================================
drift_results
| chunk | chunk_start | chunk_end | feature | ks_statistic | ks_threshold | chi2_statistic | chi2_threshold | js_statistic | js_threshold | reference_range | prop_out_of_range | max_out_of_range_proportion | is_out_of_range | drift_ks_statistic | drift_chi2_statistic | drift_js | drift_detected | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2012-01-11 | 2012-01-31 23:00:00 | temp | 0.490175 | 0.904773 | NaN | NaN | 0.546958 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 1 | 1 | 2012-02-01 | 2012-02-29 23:00:00 | temp | 0.477663 | 0.904773 | NaN | NaN | 0.523748 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 2 | 2 | 2012-03-01 | 2012-03-31 23:00:00 | temp | 0.232412 | 0.904773 | NaN | NaN | 0.373938 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 3 | 3 | 2012-04-01 | 2012-04-30 23:00:00 | temp | 0.217000 | 0.904773 | NaN | NaN | 0.455947 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 4 | 4 | 2012-05-01 | 2012-05-31 23:00:00 | temp | 0.443082 | 0.904773 | NaN | NaN | 0.539446 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 5 | 5 | 2012-06-01 | 2012-06-30 23:00:00 | temp | 0.902111 | 0.904773 | NaN | NaN | 0.877304 | 0.806410 | (0.8200000000000001, 39.36) | 0.344444 | 0.1 | True | False | False | True | True |
| 6 | 6 | 2012-07-01 | 2012-07-31 23:00:00 | temp | 1.000000 | 0.904773 | NaN | NaN | 1.000000 | 0.806410 | (0.8200000000000001, 39.36) | 1.000000 | 0.1 | True | True | False | True | True |
| 7 | 7 | 2012-08-01 | 2012-08-31 23:00:00 | temp | 0.637269 | 0.904773 | NaN | NaN | 0.652528 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 8 | 8 | 2012-09-01 | 2012-09-30 23:00:00 | temp | 0.446389 | 0.904773 | NaN | NaN | 0.518331 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 9 | 9 | 2012-10-01 | 2012-10-31 23:00:00 | temp | 0.537556 | 0.904773 | NaN | NaN | 0.863793 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | True | True |
| 10 | 10 | 2012-11-01 | 2012-11-30 23:00:00 | temp | 0.468611 | 0.904773 | NaN | NaN | 0.562611 | 0.806410 | (0.8200000000000001, 39.36) | 0.000000 | 0.1 | False | False | False | False | False |
| 11 | 11 | 2012-12-01 | 2012-12-31 23:00:00 | temp | 0.860731 | 0.904773 | NaN | NaN | 0.843966 | 0.806410 | (0.8200000000000001, 39.36) | 0.358871 | 0.1 | True | False | False | True | True |
| 12 | 0 | 2012-01-11 | 2012-01-31 23:00:00 | hum | 0.130825 | 0.385918 | NaN | NaN | 0.152290 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 13 | 1 | 2012-02-01 | 2012-02-29 23:00:00 | hum | 0.161425 | 0.385918 | NaN | NaN | 0.199334 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 14 | 2 | 2012-03-01 | 2012-03-31 23:00:00 | hum | 0.119387 | 0.385918 | NaN | NaN | 0.150733 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 15 | 3 | 2012-04-01 | 2012-04-30 23:00:00 | hum | 0.278944 | 0.385918 | NaN | NaN | 0.328472 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 16 | 4 | 2012-05-01 | 2012-05-31 23:00:00 | hum | 0.093703 | 0.385918 | NaN | NaN | 0.205141 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 17 | 5 | 2012-06-01 | 2012-06-30 23:00:00 | hum | 0.171722 | 0.385918 | NaN | NaN | 0.240059 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 18 | 6 | 2012-07-01 | 2012-07-31 23:00:00 | hum | 0.103219 | 0.385918 | NaN | NaN | 0.178075 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 19 | 7 | 2012-08-01 | 2012-08-31 23:00:00 | hum | 0.110520 | 0.385918 | NaN | NaN | 0.196713 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 20 | 8 | 2012-09-01 | 2012-09-30 23:00:00 | hum | 0.076111 | 0.385918 | NaN | NaN | 0.196889 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 21 | 9 | 2012-10-01 | 2012-10-31 23:00:00 | hum | 0.125477 | 0.385918 | NaN | NaN | 0.217908 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 22 | 10 | 2012-11-01 | 2012-11-30 23:00:00 | hum | 0.217556 | 0.385918 | NaN | NaN | 0.280111 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
| 23 | 11 | 2012-12-01 | 2012-12-31 23:00:00 | hum | 0.096502 | 0.385918 | NaN | NaN | 0.187856 | 0.423199 | (0.0, 100.0) | 0.000000 | 0.1 | False | False | False | False | False |
# Drift summary
# ==============================================================================
drift_summary
| feature | n_chunks_with_drift | pct_chunks_with_drift | chunks_with_drift | |
|---|---|---|---|---|
| 0 | hum | 0 | 0.000000 | [] |
| 1 | temp | 4 | 33.333333 | [5, 6, 9, 11] |
As expected, the detector identifies drift in the modified new data, while no drift is detected in unaltered data.
# Highlight chunks with detected drift
# ==============================================================================
set_dark_theme()
fig, ax = plt.subplots(figsize=(8, 4))
data_train.loc[:, 'temp'].plot(ax=ax, label='Train')
data_new_drift.loc[:, 'temp'].plot(ax=ax, label='New data with drift', color='red')
data_new.loc[:, 'temp'].plot(ax=ax, label='New data', color='green')
ax.axhline(data_train['temp'].max(), color='white', linestyle=':', label='Max Train')
ax.axhline(data_train['temp'].min(), color='white', linestyle=':', label='Min Train')
for row in drift_results.query('drift_detected == True').itertuples():
chunk_start = row.chunk_start
chunk_end = row.chunk_end
drift_detected = row.drift_detected
if drift_detected:
ax.axvspan(chunk_start, chunk_end, color='red', alpha=0.3, label='Drift detected')
# Remove repetitive labels in legend
handles, labels = ax.get_legend_handles_labels()
by_label = dict(zip(labels, handles))
ax.legend(by_label.values(), by_label.keys());

PopulationDriftDetector can be used with multiple time series simultaneously, each one with its own features. In this case, the input data must be a pandas DataFrame with a MultiIndex, where the first level is the series identifier, and the second level corresponds to the temporal index.
# Multi-series data
# ==============================================================================
data_multiseries = pd.concat(
[
data.assign(series='series_1'),
data.assign(series='series_2'),
data.assign(series='series_3')
]
).set_index('series', append=True).swaplevel(0,1)
display(data_multiseries)
# Split train/test per series
data_multiseries_train = (
data_multiseries
.groupby(level='series', group_keys=False)
.apply(lambda x: x.iloc[:9000])
)
data_multiseries_new = (
data_multiseries
.groupby(level='series', group_keys=False)
.apply(lambda x: x.iloc[9000:])
)
| temp | hum | ||
|---|---|---|---|
| series | date_time | ||
| series_1 | 2011-01-01 00:00:00 | 9.84 | 81.0 |
| 2011-01-01 01:00:00 | 9.02 | 80.0 | |
| 2011-01-01 02:00:00 | 9.02 | 80.0 | |
| 2011-01-01 03:00:00 | 9.84 | 75.0 | |
| 2011-01-01 04:00:00 | 9.84 | 75.0 | |
| ... | ... | ... | ... |
| series_3 | 2012-12-31 19:00:00 | 10.66 | 60.0 |
| 2012-12-31 20:00:00 | 10.66 | 60.0 | |
| 2012-12-31 21:00:00 | 10.66 | 60.0 | |
| 2012-12-31 22:00:00 | 10.66 | 56.0 | |
| 2012-12-31 23:00:00 | 10.66 | 65.0 |
52632 rows × 2 columns
# Multi-series PopulationDriftDetector
# ==============================================================================
detector = PopulationDriftDetector(
chunk_size = 'MS', # Monthly chunks
threshold = 3,
threshold_method = 'std',
max_out_of_range_proportion = 0.1
)
detector.fit(data_multiseries_train)
detector
PopulationDriftDetector
General Information
- Chunk size: MS
- Threshold: 3
- Threshold method: std
- Max out of range proportion: 0.1
- Is fitted: True
- Skforecast version: 0.23.0
Fitted features
-
{'series_1': ['temp', 'hum'], 'series_2': ['temp', 'hum'], 'series_3': ['temp', 'hum']}
# Print thresholds per series
# ==============================================================================
detector.get_thresholds()
| series_id | feature | ks_threshold | chi2_threshold | js_threshold | max_out_of_range_proportion | |
|---|---|---|---|---|---|---|
| 0 | series_1 | temp | 0.904773 | NaN | 0.806410 | 0.1 |
| 1 | series_1 | hum | 0.385918 | NaN | 0.423199 | 0.1 |
| 2 | series_2 | temp | 0.904773 | NaN | 0.806410 | 0.1 |
| 3 | series_2 | hum | 0.385918 | NaN | 0.423199 | 0.1 |
| 4 | series_3 | temp | 0.904773 | NaN | 0.806410 | 0.1 |
| 5 | series_3 | hum | 0.385918 | NaN | 0.423199 | 0.1 |
# Detect drift in new multi-series data
# ==============================================================================
drift_results, drift_summary = detector.predict(data_multiseries_new)
drift_summary
| series_id | feature | n_chunks_with_drift | pct_chunks_with_drift | chunks_with_drift | |
|---|---|---|---|---|---|
| 0 | series_1 | hum | 0 | 0.0 | [] |
| 1 | series_1 | temp | 0 | 0.0 | [] |
| 2 | series_2 | hum | 0 | 0.0 | [] |
| 3 | series_2 | temp | 0 | 0.0 | [] |
| 4 | series_3 | hum | 0 | 0.0 | [] |
| 5 | series_3 | temp | 0 | 0.0 | [] |
Drift detection during prediction¶
Skforecast provides the class RangeDriftDetector to detect covariate drift in both single and multiple time series, as well as in exogenous variables.
The detector checks whether the input data (lags and exogenous variables) used to predict new values fall within the range of the data used to train the model.
Its API follows the same design as the forecasters:
The data used to train a forecaster can also be used to fit the
RangeDriftDetector.The data passed to the forecaster's
predictmethod can be also passed to theRangeDriftDetector'spredictmethod to check for drift in the input data before making predictions.If drift is detected, users should analyze its cause and consider whether the model is still appropriate for making predictions with the new data.
# Libraries
# ==============================================================================
from sklearn.ensemble import HistGradientBoostingRegressor
from skforecast.recursive import ForecasterRecursive
from skforecast.drift_detection import RangeDriftDetector
Detecting out-of-range values in a single series¶
The RangeDriftDetector checks whether the values of a time series remain consistent with the data seen during training.
For numeric variables, it verifies that each new value falls within the minimum and maximum range of the training data. Values outside this range are flagged as potential drift.
For categorical variables, it checks whether each new category was observed during training. Unseen categories are flagged as potential drift.
This mechanism allows you to quickly identify when the model is receiving inputs that differ from those it was trained on, helping you decide whether to retrain the model or adjust preprocessing.
# Simulated data
# ==============================================================================
rgn = np.random.default_rng(123)
y_train = pd.Series(
rgn.normal(loc=10, scale=2, size=100),
index=pd.date_range(start="2020-01-01", periods=100),
name="y",
)
exog_train = pd.DataFrame(
{
"exog_1": rgn.normal(loc=10, scale=2, size=100),
"exog_2": rgn.choice(["A", "B", "C", "D", "E"], size=100),
},
index=y_train.index,
)
display(y_train.head())
display(exog_train.head())
2020-01-01 8.021757 2020-01-02 9.264427 2020-01-03 12.575851 2020-01-04 10.387949 2020-01-05 11.840462 Freq: D, Name: y, dtype: float64
| exog_1 | exog_2 | |
|---|---|---|
| 2020-01-01 | 8.968465 | B |
| 2020-01-02 | 13.316227 | B |
| 2020-01-03 | 9.405475 | A |
| 2020-01-04 | 7.233246 | A |
| 2020-01-05 | 9.437591 | A |
# Train RangeDriftDetector
# ==============================================================================
detector = RangeDriftDetector()
detector.fit(y=y_train, exog=exog_train)
detector
RangeDriftDetector
General Information
- Fitted series: y
- Fitted exogenous: exog_1, exog_2
- Series-specific exogenous: False
- Is fitted: True
- Skforecast version: 0.23.0
Series value ranges
-
{'y': (5.5850578036003915, 14.579819894629157)}
Exogenous value ranges
-
{'exog_1': (4.5430286262543085, 14.531041199734418), 'exog_2': {'C', 'B', 'A', 'D', 'E'}}
Let's assume the model is deployed in production and new data is being used to forecast future values. We simulate a covariate drift in the target series and in the exogenous variables to illustrate how to use the RangeDriftDetector class to detect it.
# Prediction with drifted data
# ==============================================================================
last_window = pd.Series(
[6.6, 7.5, 100, 9.3, 10.2], name="y" # Value 100 is out of range
)
exog_predict = pd.DataFrame(
{
"exog_1": [8, 9, 10, 70, 12], # Value 70 is out of range
"exog_2": ["A", "B", "C", "D", "W"], # Value 'W' is out of range
}
)
flag_out_of_range, series_out_of_range, exog_out_of_range = detector.predict(
last_window = last_window,
exog = exog_predict,
verbose = True,
suppress_warnings = False
)
print("Out of range detected :", flag_out_of_range)
print("Series out of range :", series_out_of_range)
print("Exogenous out of range :", exog_out_of_range)
╭────────────────────────────── FeatureOutOfRangeWarning ──────────────────────────────╮ │ 'y' has values outside the range seen during training [5.58506, 14.57982]. This may │ │ affect the accuracy of the predictions. │ │ │ │ Category : skforecast.exceptions.FeatureOutOfRangeWarning │ │ Location : │ │ /home/ubuntu/miniconda3/envs/cienciadedatos/lib/python3.13/site-packages/skforecast/ │ │ drift_detection/_range_drift.py:284 │ │ Suppress : warnings.simplefilter('ignore', category=FeatureOutOfRangeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────── FeatureOutOfRangeWarning ──────────────────────────────╮ │ 'exog_1' has values outside the range seen during training [4.54303, 14.53104]. This │ │ may affect the accuracy of the predictions. │ │ │ │ Category : skforecast.exceptions.FeatureOutOfRangeWarning │ │ Location : │ │ /home/ubuntu/miniconda3/envs/cienciadedatos/lib/python3.13/site-packages/skforecast/ │ │ drift_detection/_range_drift.py:284 │ │ Suppress : warnings.simplefilter('ignore', category=FeatureOutOfRangeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────── FeatureOutOfRangeWarning ──────────────────────────────╮ │ 'exog_2' has values not seen during training. Seen values: {'C', 'B', 'A', 'D', │ │ 'E'}. This may affect the accuracy of the predictions. │ │ │ │ Category : skforecast.exceptions.FeatureOutOfRangeWarning │ │ Location : │ │ /home/ubuntu/miniconda3/envs/cienciadedatos/lib/python3.13/site-packages/skforecast/ │ │ drift_detection/_range_drift.py:284 │ │ Suppress : warnings.simplefilter('ignore', category=FeatureOutOfRangeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭───────────────────────────── Out-of-range summary ──────────────────────────────╮ │ Series: │ │ 'y' has values outside the observed range [5.58506, 14.57982]. │ │ │ │ Exogenous Variables: │ │ 'exog_1' has values outside the observed range [4.54303, 14.53104]. │ │ 'exog_2' has values not seen during training. Seen values: {'C', 'B', 'A', 'D', │ │ 'E'}. │ ╰─────────────────────────────────────────────────────────────────────────────────╯
Out of range detected : True Series out of range : ['y'] Exogenous out of range : ['exog_1', 'exog_2']
Detecting out-of-range values in multiple series¶
The same process applies when modeling multiple time series.
For each series, the
RangeDriftDetectorchecks whether the new values remain within the range of the training data.If exogenous variables are included, they are checked grouped by series, ensuring that drift is detected in the correct context.
This allows you to monitor drift at the per-series level, making it easier to spot issues in specific series without being misled by aggregated results.
# Simulated data - Multiple time series
# ==============================================================================
idx = pd.MultiIndex.from_product(
[
["series_1", "series_2", "series_3"],
pd.date_range(start="2020-01-01", periods=3),
],
names=["series_id", "datetime"],
)
series_train = pd.DataFrame(
{"values": [1, 2, 3, 10, 20, 30, 100, 200, 300]}, index=idx
)
exog_train = pd.DataFrame(
{
"exog_1": [5.0, 6.0, 7.0, 15.0, 25.0, 35.0, 150.0, 250.0, 350.0],
"exog_2": ["A", "B", "C", "D", "E", "F", "G", "H", "I"],
},
index=idx,
)
display(series_train)
display(exog_train)
| values | ||
|---|---|---|
| series_id | datetime | |
| series_1 | 2020-01-01 | 1 |
| 2020-01-02 | 2 | |
| 2020-01-03 | 3 | |
| series_2 | 2020-01-01 | 10 |
| 2020-01-02 | 20 | |
| 2020-01-03 | 30 | |
| series_3 | 2020-01-01 | 100 |
| 2020-01-02 | 200 | |
| 2020-01-03 | 300 |
| exog_1 | exog_2 | ||
|---|---|---|---|
| series_id | datetime | ||
| series_1 | 2020-01-01 | 5.0 | A |
| 2020-01-02 | 6.0 | B | |
| 2020-01-03 | 7.0 | C | |
| series_2 | 2020-01-01 | 15.0 | D |
| 2020-01-02 | 25.0 | E | |
| 2020-01-03 | 35.0 | F | |
| series_3 | 2020-01-01 | 150.0 | G |
| 2020-01-02 | 250.0 | H | |
| 2020-01-03 | 350.0 | I |
# Train RangeDriftDetector - Multiple time series
# ==============================================================================
detector = RangeDriftDetector()
detector.fit(series=series_train, exog=exog_train)
# Prediction with drifted data - Multiple time series
# ==============================================================================
last_window = pd.DataFrame(
{
"series_1": np.array([1.5, 2.3]),
"series_2": np.array([100, 20]), # Value 100 is out of range
"series_3": np.array([110, 200]),
},
index=pd.date_range(start="2020-01-02", periods=2),
)
idx = pd.MultiIndex.from_product(
[
["series_1", "series_2", "series_3"],
pd.date_range(start="2020-01-04", periods=2),
],
names=["series_id", "datetime"],
)
exog_predict = pd.DataFrame(
{
"exog_1": [5.0, 6.1, 10, 70, 220, 290],
"exog_2": ["A", "B", "D", "F", "W", "E"],
},
index=idx,
)
display(last_window)
display(exog_predict)
| series_1 | series_2 | series_3 | |
|---|---|---|---|
| 2020-01-02 | 1.5 | 100 | 110 |
| 2020-01-03 | 2.3 | 20 | 200 |
| exog_1 | exog_2 | ||
|---|---|---|---|
| series_id | datetime | ||
| series_1 | 2020-01-04 | 5.0 | A |
| 2020-01-05 | 6.1 | B | |
| series_2 | 2020-01-04 | 10.0 | D |
| 2020-01-05 | 70.0 | F | |
| series_3 | 2020-01-04 | 220.0 | W |
| 2020-01-05 | 290.0 | E |
# Prediction with drifted data - Multiple time series
# ==============================================================================
flag_out_of_range, series_out_of_range, exog_out_of_range = detector.predict(
last_window = last_window,
exog = exog_predict,
verbose = True,
suppress_warnings = False
)
print("Out of range detected :", flag_out_of_range)
print("Series out of range :", series_out_of_range)
print("Exogenous out of range :", exog_out_of_range)
╭────────────────────────────── FeatureOutOfRangeWarning ──────────────────────────────╮ │ 'series_2' has values outside the range seen during training [10.00000, 30.00000]. │ │ This may affect the accuracy of the predictions. │ │ │ │ Category : skforecast.exceptions.FeatureOutOfRangeWarning │ │ Location : │ │ /home/ubuntu/miniconda3/envs/cienciadedatos/lib/python3.13/site-packages/skforecast/ │ │ drift_detection/_range_drift.py:284 │ │ Suppress : warnings.simplefilter('ignore', category=FeatureOutOfRangeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────── FeatureOutOfRangeWarning ──────────────────────────────╮ │ 'series_2': 'exog_1' has values outside the range seen during training [15.00000, │ │ 35.00000]. This may affect the accuracy of the predictions. │ │ │ │ Category : skforecast.exceptions.FeatureOutOfRangeWarning │ │ Location : │ │ /home/ubuntu/miniconda3/envs/cienciadedatos/lib/python3.13/site-packages/skforecast/ │ │ drift_detection/_range_drift.py:284 │ │ Suppress : warnings.simplefilter('ignore', category=FeatureOutOfRangeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────── FeatureOutOfRangeWarning ──────────────────────────────╮ │ 'series_3': 'exog_2' has values not seen during training. Seen values: {'H', 'G', │ │ 'I'}. This may affect the accuracy of the predictions. │ │ │ │ Category : skforecast.exceptions.FeatureOutOfRangeWarning │ │ Location : │ │ /home/ubuntu/miniconda3/envs/cienciadedatos/lib/python3.13/site-packages/skforecast/ │ │ drift_detection/_range_drift.py:284 │ │ Suppress : warnings.simplefilter('ignore', category=FeatureOutOfRangeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────── Out-of-range summary ──────────────────────────────╮ │ Series: │ │ 'series_2' has values outside the observed range [10.00000, 30.00000]. │ │ │ │ Exogenous Variables: │ │ 'series_2': 'exog_1' has values outside the observed range [15.00000, 35.00000]. │ │ 'series_3': 'exog_2' has values not seen during training. Seen values: {'H', │ │ 'G', 'I'}. │ ╰──────────────────────────────────────────────────────────────────────────────────╯
Out of range detected : True
Series out of range : ['series_2']
Exogenous out of range : {'series_2': ['exog_1'], 'series_3': ['exog_2']}
Combining RangeDriftDetector with Forecasters¶
When deploying a forecaster in production, it is good practice to pair it with a drift detector. This ensures that both are trained on the same dataset, allowing the drift detector to verify the input data before the forecaster makes predictions.
# Data
# ==============================================================================
data = fetch_dataset(name='h2o_exog', verbose=False)
data.index.name = 'datetime'
data.head(3)
| y | exog_1 | exog_2 | |
|---|---|---|---|
| datetime | |||
| 1992-04-01 | 0.379808 | 0.958792 | 1.166029 |
| 1992-05-01 | 0.361801 | 0.951993 | 1.117859 |
| 1992-06-01 | 0.410534 | 0.952955 | 1.067942 |
# Train Forecaster and RangeDriftDetector
# ==============================================================================
steps = 36
data_train = data.iloc[:-steps, :]
data_test = data.iloc[-steps:, :]
forecaster = ForecasterRecursive(
estimator = HistGradientBoostingRegressor(random_state=123),
lags = 15
)
detector = RangeDriftDetector()
forecaster.fit(
y = data_train['y'],
exog = data_train[['exog_1', 'exog_2']]
)
detector.fit(
series = data_train['y'],
exog = data_train[['exog_1', 'exog_2']]
)
If you use the last_window stored in the Forecaster, drift detection is unnecessary because it corresponds to the final window of the training data. In production environments, however, you may supply an external last_window from a different time period. In that case, drift detection is recommended.
In the example below, the external last_window is identical to the final training window, so no drift will be detected.
# Last window (same as forecaster.last_window_)
# ==============================================================================
last_window = data_train['y'].iloc[-forecaster.max_lag:]
last_window
datetime 2004-04-01 0.739986 2004-05-01 0.795129 2004-06-01 0.856803 2004-07-01 1.001593 2004-08-01 0.994864 2004-09-01 1.134432 2004-10-01 1.181011 2004-11-01 1.216037 2004-12-01 1.257238 2005-01-01 1.170690 2005-02-01 0.597639 2005-03-01 0.652590 2005-04-01 0.670505 2005-05-01 0.695248 2005-06-01 0.842263 Freq: MS, Name: y, dtype: float64
# Check data with RangeDriftDetector and predict with Forecaster
# ==============================================================================
detector.predict(
last_window = last_window,
exog = data_test[['exog_1', 'exog_2']],
verbose = True,
suppress_warnings = False
)
predictions = forecaster.predict(
steps = 36,
last_window = last_window,
exog = data_test[['exog_1', 'exog_2']]
)
╭───────────────── Out-of-range summary ─────────────────╮ │ Series: │ │ No series with out-of-range values found. │ │ │ │ Exogenous Variables: │ │ No exogenous variables with out-of-range values found. │ ╰────────────────────────────────────────────────────────╯
Session information¶
import session_info
session_info.show(html=False)
----- matplotlib 3.11.0 numpy 2.4.6 pandas 2.3.3 scipy 1.18.0 seaborn 0.13.2 session_info v1.0.1 skforecast 0.23.0 sklearn 1.7.2 ----- IPython 9.15.0 jupyter_client 8.9.1 jupyter_core 5.9.1 ----- Python 3.13.14 | packaged by conda-forge | (main, Jun 12 2026, 09:50:25) [GCC 14.3.0] Linux-7.0.0-1008-aws-x86_64-with-glibc2.43 ----- Session information updated at 2026-07-14 00:32
Citation¶
How to cite this document
If you use this document or any part of it, please acknowledge the source, thank you!
Data drift detection in time series forecasting models by Joaquín Amat Rodrigo and Javier Escobar Ortiz, available under a Attribution-NonCommercial-ShareAlike 4.0 International at https://www.cienciadedatos.net/documentos/py70-drift-detection-forecasting-model.html
How to cite skforecast
If you use skforecast for a publication, we would appreciate it if you cite the published software.
Zenodo:
Amat Rodrigo, Joaquin, & Escobar Ortiz, Javier. (2025). skforecast (v0.23.0). Zenodo. https://doi.org/10.5281/zenodo.8382788
APA:
Amat Rodrigo, J., & Escobar Ortiz, J. (2025). skforecast (Version 0.23.0) [Computer software]. https://doi.org/10.5281/zenodo.8382788
BibTeX:
@software{skforecast, author = {Amat Rodrigo, Joaquin and Escobar Ortiz, Javier}, title = {skforecast}, version = {0.23.0}, month = {07}, year = {2026}, license = {BSD-3-Clause}, url = {https://skforecast.org/}, doi = {10.5281/zenodo.8382788} }
Did you like the article? Your support is important
Your contribution will help me to continue generating free educational content. Many thanks! 😊




This work by Joaquín Amat Rodrigo and Javier Escobar Ortiz is licensed under a Attribution-NonCommercial-ShareAlike 4.0 International.
Allowed:
-
Share: copy and redistribute the material in any medium or format.
-
Adapt: remix, transform, and build upon the material.
Under the following terms:
-
Attribution: You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
-
NonCommercial: You may not use the material for commercial purposes.
-
ShareAlike: If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.